### 2021.12.18
- NumPy의 배열 연산은 벡터화(vectorized) 연산을 사용
- 일반적으로 NumPy의 범용 함수(universal functions)를 통해 구현
- 배열 요소에 대한 반복적인 계산을 효율적으로 수행
브로드캐스팅(Broadcasting)

#In[]
import numpy as np
a1 = np.array([1,2,3])
print(a1)
print(a1 + 5)
#Out[]
[1 2 3]
[6 7 8]#In[]
a2 = np.arange(1,10).reshape(3,3)
print(a2)
print(a1 + a2)
#Out[]
[[1 2 3]
[4 5 6]
[7 8 9]]
[[ 2 4 6]
[ 5 7 9]
[ 8 10 12]]#In[]
b2 = np.array([1,2,3]).reshape(3,1)
print(b2)
print(a1 + b2)
#Out[]
[[1]
[2]
[3]]
[[2 3 4]
[3 4 5]
[4 5 6]]
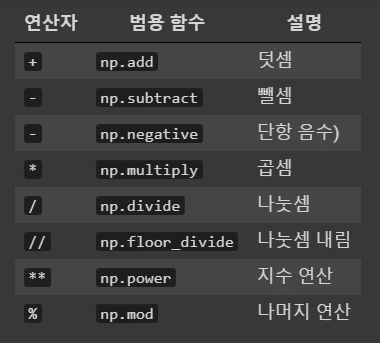
산술 연산(Arithmetic Operators)
#In[]
a1 = np.arange(1,10)
print(a1)
print(a1 + 1)
print(np.add(a1, 10))
#Out[]
[1 2 3 4 5 6 7 8 9]
[ 2 3 4 5 6 7 8 9 10]
[11 12 13 14 15 16 17 18 19]#In[]
print(a1 - 2)
print(np.subtract(a1, 10))
#Out[]
[-1 0 1 2 3 4 5 6 7]
[-9 -8 -7 -6 -5 -4 -3 -2 -1]#In[]
print(-a1)
print(np.negative(a1))
#Out[]
[-1 -2 -3 -4 -5 -6 -7 -8 -9]
[-1 -2 -3 -4 -5 -6 -7 -8 -9]#In[]
print(a1 * 2)
print(np.multiply(a1, 2))
#Out[]
[ 2 4 6 8 10 12 14 16 18]
[ 2 4 6 8 10 12 14 16 18]#In[]
print(a1 / 2)
print(np.divide(a1, 2))
#Out[]
[0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5]
[0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5]#In[]
print(a1 // 2)
print(np.floor_divide(a1,2))
#Out[]
[0 1 1 2 2 3 3 4 4]
[0 1 1 2 2 3 3 4 4]
#In[]
print(a1 ** 2)
print(np.power(a1, 2))
#Out[]
[ 1 4 9 16 25 36 49 64 81]
[ 1 4 9 16 25 36 49 64 81]#In[]
print(a1 % 2)
print(np.mod(a1,2))
#Out[]
[1 0 1 0 1 0 1 0 1]
[1 0 1 0 1 0 1 0 1]# 배열간의 연산도 가능하다
#In[]
a1 = np.arange(1, 10)
print(a1)
b1 = np.random.randint(1, 10, size=9)
print(b1)
print(a1 + b1)
print(a1 - b1)
print(a1 * b1)
print(a1 / b1)
print(a1 // b1)
print(a1 ** b1)
print(a1 % b1)
#Out[]
[1 2 3 4 5 6 7 8 9]
[7 8 8 6 6 5 1 7 1]
[ 8 10 11 10 11 11 8 15 10]
[-6 -6 -5 -2 -1 1 6 1 8]
[ 7 16 24 24 30 30 7 56 9]
[0.14285714 0.25 0.375 0.66666667 0.83333333 1.2
7. 1.14285714 9. ]
[0 0 0 0 0 1 7 1 9]
[ 1 256 6561 4096 15625 7776 7 2097152 9]
[1 2 3 4 5 1 0 1 0]# 2차원에서도 가능!!
#In[]
a2 = np.arange(1,10).reshape(3,3)
print(a2)
b2 = np.random.randint(1, 10, size=(3,3))
print(b2)
print(a2 + b2)
print(a2 - b2)
#Out[]
[[1 2 3]
[4 5 6]
[7 8 9]]
[[4 6 3]
[4 7 3]
[4 4 8]]
[[ 5 8 6]
[ 8 12 9]
[11 12 17]]
[[-3 -4 0]
[ 0 -2 3]
[ 3 4 1]]절대값 함수(Absolute Function)
- absolute(), abs(): 내장된 절대값 함수
#In[]
a1 = np.random.randint(-10, 10, size=5)
print(a1)
print(np.absolute(a1))
print(np.abs(a1))
#Out[]
[-10 5 2 -9 2]
[10 5 2 9 2]
[10 5 2 9 2]제곱/제곱근 함수
- square, sqrt: 제곱, 제곱근 함수
#In[]
print(a1)
print(np.square(a1))
print((np.sqrt(np.abs(a1))))
#Out[]
[-10 5 2 -9 2]
[100 25 4 81 4]
[3.16227766 2.23606798 1.41421356 3. 1.41421356]지수와 로그 함수 (Exponential and Log Function)
#In[]
a1 = np.random.randint(1, 10, size=5)
print(a1)
print(np.exp(a1))
print(np.exp2(a1))
print(np.power(a1,2))
#Out[]
[1 6 2 1 9]
[2.71828183e+00 4.03428793e+02 7.38905610e+00 2.71828183e+00
8.10308393e+03]
[ 2. 64. 4. 2. 512.]
[ 1 36 4 1 81]#In[]
print(a1)
print(np.log(a1))
print(np.log2(a1))
print(np.log10(a1))
#Out[]
[1 6 2 1 9]
[0. 1.79175947 0.69314718 0. 2.19722458]
[0. 2.5849625 1. 0. 3.169925 ]
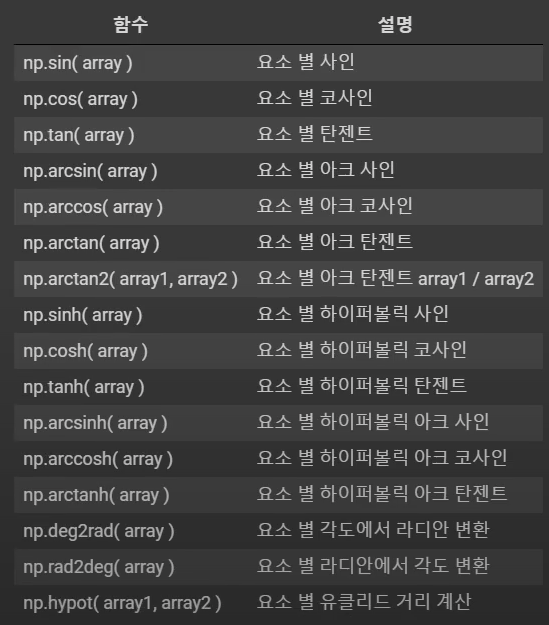
[0. 0.77815125 0.30103 0. 0.95424251]삼각 함수(Trigonometrical Function)
#In[]
t = np.linspace(0, np.pi, 3)
print(t)
print(np.sin(t))
print(np.cos(t))
print(np.tan(t))
#Out[]
[0. 1.57079633 3.14159265]
[0.0000000e+00 1.0000000e+00 1.2246468e-16]
[ 1.000000e+00 6.123234e-17 -1.000000e+00]
[ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]#In[]
x = [-1, 0, 1]
print(x)
print(np.arcsin(x))
print(np.arccos(x))
print(np.arctan(x))
#Out[]
[-1, 0, 1]
[-1.57079633 0. 1.57079633]
[3.14159265 1.57079633 0. ]
[-0.78539816 0. 0.78539816]
집계 함수(Aggregate Functions)
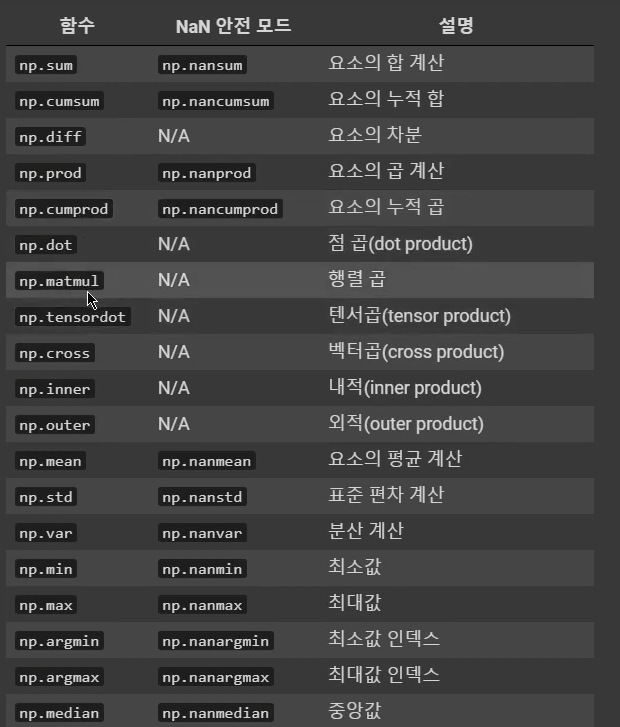

sum(): 합 계산
#In[]
a2 = np.random.randint(1, 10, size=(3,3))
print(a2)
print(a2.sum(), np.sum(a2))
print(a2.sum(axis=0), np.sum(a2, axis=0))
print(a2.sum(axis=1), np.sum(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
39 39
[ 8 14 17] [ 8 14 17]
[11 15 13] [11 15 13]cumsum(): 누적합 계산
#In[]
print(a2)
print(np.cumsum(a2))
print(np.cumsum(a2, axis=0))
print(np.cumsum(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[ 2 4 11 15 20 26 28 35 39]
[[ 2 2 7]
[ 6 7 13]
[ 8 14 17]]
[[ 2 4 11]
[ 4 9 15]
[ 2 9 13]]diff(): 차분 계산
#In[]
print(a2)
print(np.diff(a2))
print(np.diff(a2, axis=0))
print(np.diff(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[[ 0 5]
[ 1 1]
[ 5 -3]]
[[ 2 3 -1]
[-2 2 -2]]
[[ 0 5]
[ 1 1]
[ 5 -3]]prod(): 곱 계산
#In[]
print(a2)
print(np.prod(a2))
print(np.prod(a2, axis=0))
print(np.prod(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
188160
[ 16 70 168]
[ 28 120 56]cumprod(): 누적곱 계산
#In[]
print(a2)
print(np.cumprod(a2))
print(np.cumprod(a2, axis=0))
print(np.cumprod(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[ 2 4 28 112 560 3360 6720 47040 188160]
[[ 2 2 7]
[ 8 10 42]
[ 16 70 168]]
[[ 2 4 28]
[ 4 20 120]
[ 2 14 56]]dot()/matmul(): 점곱/행렬곱 계산
#In[]
b2 = np. ones_like(a2)
print(a2)
print(b2)
print(np.dot(a2, b2))
print(np.matmul(a2, b2))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[[1 1 1]
[1 1 1]
[1 1 1]]
[[11 11 11] # 2*1 + 2*1 + 7*1
[15 15 15] # 4*1 + 5*1 + 6*1
[13 13 13]] # 2*1 + 7*1 + 4*1
[[11 11 11]
[15 15 15]
[13 13 13]]tensordot(): 텐서곱 계산
#In[]
print(a2)
print(b2)
print(np.tensordot(a2,b2))
print(np.tensordot(a2,b2, axes=0))
print(np.tensordot(a2,b2, axes=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[[1 1 1]
[1 1 1]
[1 1 1]]
39 #행렬곱하고 더하기!
[[[[2 2 2]
[2 2 2]
[2 2 2]]
[[2 2 2]
[2 2 2]
[2 2 2]]
[[7 7 7]
[7 7 7]
[7 7 7]]]
[[[4 4 4]
[4 4 4]
[4 4 4]]
[[5 5 5]
[5 5 5]
[5 5 5]]
[[6 6 6]
[6 6 6]
[6 6 6]]]
[[[2 2 2]
[2 2 2]
[2 2 2]]
[[7 7 7]
[7 7 7]
[7 7 7]]
[[4 4 4]
[4 4 4]
[4 4 4]]]]
-----------------------
[[11 11 11]
[15 15 15]
[13 13 13]]cross(): 벡터곱
#In[]
x = [1,2,3]
y = [4,5,6]
print(np.cross(x,y))
#Out[]
[-3 6 -3]
# 2*6 - 3*5 = -3
# 3*4 - 1*6 = 6
# 1*5 - 2*4 = -3inner()/outer(): 내적/외적
#In[]
print(a2)
print(b2)
print(np.inner(a2,b2))
print(np.outer(a2,b2))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
[[1 1 1]
[1 1 1]
[1 1 1]]
[[11 11 11]
[15 15 15]
[13 13 13]]
[[2 2 2 2 2 2 2 2 2]
[2 2 2 2 2 2 2 2 2]
[7 7 7 7 7 7 7 7 7]
[4 4 4 4 4 4 4 4 4]
[5 5 5 5 5 5 5 5 5]
[6 6 6 6 6 6 6 6 6]
[2 2 2 2 2 2 2 2 2]
[7 7 7 7 7 7 7 7 7]
[4 4 4 4 4 4 4 4 4]]mean(): 평균 계산
#In[]
print(a2)
print(np.mean(a2))
print(np.mean(a2, axis=0))
print(np.mean(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
4.333333333333333
[2.66666667 4.66666667 5.66666667]
[3.66666667 5. 4.33333333]std(): 표준 편차 계산
#In[]
print(a2)
print(np.std(a2))
print(np.std(a2, axis=0))
print(np.std(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
1.9436506316151
[0.94280904 2.05480467 1.24721913]
[2.3570226 0.81649658 2.05480467]var(): 분산 계산
#In[]
print(a2)
print(np.var(a2))
print(np.var(a2, axis=0))
print(np.var(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
3.7777777777777777
[0.88888889 4.22222222 1.55555556]
[5.55555556 0.66666667 4.22222222]min(): 최소값
#In[]
print(a2)
print(np.min(a2))
print(np.min(a2, axis=0))
print(np.min(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
2
[2 2 4]
[2 4 2]max(): 최대값
#In[]
print(a2)
print(np.max(a2))
print(np.max(a2, axis=0))
print(np.max(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
7
[4 7 7]
[7 6 7]argmin(): 최소값 인덱스
#In[]
print(a2)
print(np.argmin(a2))
print(np.argmin(a2, axis=0))
print(np.argmin(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
0
[0 0 2]
[0 0 0]
#최소값이 있는 인덱스값을 출력argmax(): 최대값 인덱스
#In[]
print(a2)
print(np.argmax(a2))
print(np.argmax(a2, axis=0))
print(np.argmax(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
2
[1 2 0]
[2 2 1]
#최대값이 있는 인덱스값을 출력median(): 중앙값
#In[]
print(a2)
print(np.median(a2))
print(np.median(a2, axis=0))
print(np.median(a2, axis=1))
#Out[]
[[2 2 7]
[4 5 6]
[2 7 4]]
4.0
[2. 5. 6.]
[2. 5. 4.]percentile(): 백분위 수
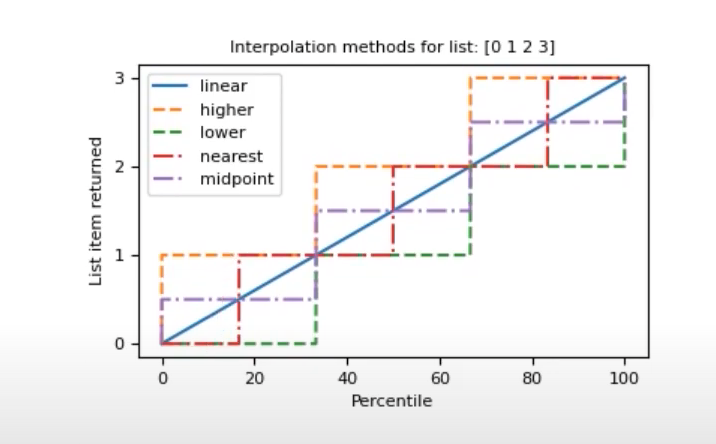
#In[]
a1 = np.array([0,1,2,3])
print(a1)
print(np.percentile(a1, [0,20,40,60,80,100], interpolation= 'linear'))
print(np.percentile(a1, [0,20,40,60,80,100], interpolation= 'higher'))
print(np.percentile(a1, [0,20,40,60,80,100], interpolation= 'lower'))
print(np.percentile(a1, [0,20,40,60,80,100], interpolation= 'nearest'))
print(np.percentile(a1, [0,20,40,60,80,100], interpolation= 'midpoint'))
#Out[]
[0 1 2 3]
[0. 0.6 1.2 1.8 2.4 3. ]
[0 1 2 2 3 3]
[0 0 1 1 2 3]
[0 1 1 2 2 3]
[0. 0.5 1.5 1.5 2.5 3. ]any()
#In[]
a2 = np.array([[False, False, False],
[False, True, True],
[False, True, True]])
print(a2)
print(np.any(a2))
print(np.any(a2, axis=0))
print(np.any(a2, axis=1))
#한개라도 True가 있다면 True
#모두 False여야 False
#Out[]
[[False False False]
[False True True]
[False True True]]
True
[False True True]
[False True True]all()
#In[]
a2 = np.array([[False, False, True],
[True, True, True],
[False, True, True]])
print(a2)
print(np.all(a2))
print(np.all(a2, axis=0))
print(np.all(a2, axis=1))
#모두 True여야 True
#한개라도 False가 있다 False
#Out[]
[[False False True]
[ True True True]
[False True True]]
False
[False False True]
[False True False]1:55:36
비교 연산(Comparison Operators)
#In[]
#Out[]#In[]
#Out[]#In[]
#Out[]#In[]
#Out[]
'Youtube > NumPy' 카테고리의 다른 글
| [NumPy] #4 배열 변환 (0) | 2021.12.18 |
|---|---|
| [Numpy] #3 배열 값 삽입/수정/삭제/복사 (0) | 2021.12.18 |
| [NumPy] #2 배열조회 (0) | 2021.12.16 |